프로젝트를 진행하면서 refresh token을 사용하여 access token을 재발급 하는 로직을 구현하려 했다.
refresh token 테이블을 따로 만들어서 관리를 하려 했는데, 그렇게 되면 사용자가 로그인, 로그아웃, 토큰 재발급을 받을 때마다 테이블에 접근해야 하고 따로 일일이 삭제도 진행해 줘야 하니 너무 비효율적이란 생각이 들게 됐다.
그래서 유효기간을 정해놓고 잠깐 동안만 저장해 둘 수 있는 캐시를 사용해 보자 마음 먹었고 redis를 프로젝트에 적용시키게 됐다.
Redis 란?
redis는 in-memory database이다. 메모리에 위치한다는 것으로 redis의 속도가 빠르다는 것을 예측할 수 있다.

평균 작업 속도가 1 ms 이하로 초당 수백만 건의 작업이 가능하다.
메모리에 위치한다는 것은 데이터가 영구적이지 않다는 것을 의미한다.
필자는 캐시로 redis를 사용할 예정이니 영구 저장 방법을 알 필요는 없지만 나중을 위해서 영구 저장 방법을 알아 보도록 하자.
Redis 데이터 영구 저장 방법
AOF vs RDB
AOF( Append Only File) 말 그대로 추가만 가능한 파일로 데이터의 추가 삭제등 모든 로그를 기록하는 방식이다.
데이터가 모두 저장 되기 때문에 RDB 보다 파일의 크기가 크며, 주기적으로 압축해줘야 한다는 단점이 있다.
RDB(Redis DataBase) 는 스냅샷 방식으로 동작한다. 간단하게 말하면 저장 당시 데이터 그대로를 저장한다는 의미이다.
모든 데이터가 저장되지 않기 때문에 AOF보다 크기가 작다는 장점이 있지만, 스냅샷 이전의 데이터는 복구할 수 없다는 단점을 가지고 있다.

위 사진을 보면 알 수 있듯이 AOF 방식으로 저장하면 key1의 저장과 key2의 저장 삭제 모든 과정이 기록돼 있는 것을 확인 할 수 있고, RDB 방식에서는 key2가 삭제됐기에 key1에 대한 정보만 남아 있는 것을 확인할 수 있다.
파일 생성 방법
두 방법 모두 커맨드를 이용해 수동으로 파일을 생성할 수도 있고 자동으로 파일이 생성되게 할 수도 있다.
RDB:
자동: redis.conf 파일에서 SAVE 옵션을 통해 파일을 자동 생성할 수 있다. (시간을 기준으로 동작함)
수동: BGSAVE 커맨드를 이용해 cli 창에서 수동으로 RDB 파일을 생성할 수 있다.
AOF:
자동: redis.conf 파일에서 auto-aof-rewirte-percentage 옵션을 통해 파일을 자동 생성할 수 있다. (파일의 크기를 기준으로 동작한다)
수동: BGREWRITEAOF 커맨드를 이용해 cli 창에서 수동으로 AOF 파일을 생성할 수 있다.
RDB vs AOF 선택 기준
백업은 필요하지만 어느 정도의 데이터 손실이 발생해도 괜찮은 경우
-> RDB만 단독으로 사용한다.
장애 상황 직전까지의 모든 데이터가 보장되어야 할 경우
-> AOF를 사용한다.
-> 기본 설정으로 APPENDSYNC 옵션이 everysec로 돼있어 1초 단위로 데이터를 기록하기에 최대 데이터 유실이 1초 사이가 된다.
Redis 아키텍쳐의 종류
1. Replication

다음과 같이 replica만 존재하는 단순한 구성이다.
1. replicaof 커맨드를 이용해 간단하게 해당 redis를 replica로 설정할 수 있다.
2. 비동기식으로 동작한다.
3. HA 기능이 없어 장애 상황 시 수동으로 복구해줘야 한다.
- replicaof no one 명령어를 통해 replica의 복제 모드를 종료시켜 준다.
- 어플리케이션에서 redis 연결 정보를 replica였던 것으로 바꿔 주어야 한다.
2. Sentinel
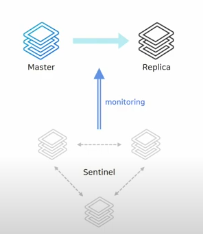
자동 복구가 가능한 HA 구성이다.
1. sentinel 노드가 다른 노드를 감시한다.
2. 마스터가 비정상 상태일 때 자동으로 복구를 시도한다.
3. 연결 정보 변경은 필요 없다.
4. sentinel 노드는 항상 3대 이상의 홀수로 존재해야 한다.
- 과반수 이상의 sentinel이 동의해야 복구를 진행한다.
3. Cluster

여러 서버에 데이터를 분산하여 저장하는 방식을 의미한다.
1. 키를 여러 노드에 자동으로 분할해서 저장하는 샤딩 기능의 제공한다.
2. 모든 노드가 서로를 감시하여, 마스터노드가 비정상 상태일 때 자동으로 복구를 시도한다.
3. 최소 3대의 마스터 노드가 필요하다.
아키텍쳐 선정 기준

NHN cloud 에서는 다음과 같은 방식을 사용한다고 한다.
필자는 토큰 재발급과 로그아웃 기능 구현을 위해 redis를 사용할 예정이니 Stand-Alone 즉 master 노드 한 개만 두는 방식을 사용할 예정이다.
Redis에서 지원하는 자료형

String: 카운팅이 필요한 상황에 유용하다. key 하나를 만들어서 카운팅할 상황마다 increment 함수를 사용하여 하나씩 카운팅 하면 손 쉽게 카운팅이 가능하다.
Bits: 데이터 저장공간을 절약해야 하는 상황에서 유용하다. 예를 들어 특정 날짜에 접속한 회원의 숫자를 알고 싶다면 접속한 회원을 1로 저장해둔 뒤 1만 카운트 하면 저장공간을 엄청나게 절약해서 카운팅을 할 수 있다.
Redis의 특징과 소소한 사용 팁
싱글 스레드
redis는 싱글 스레드로 동작한다. 즉 한 가지 작업을 수행 중일 때 다른 작업을 수행할 수 없다는 것이다.
장점: 컨텍스트 스위칭과 교착상태가 발생하지 않기에 리소스를 효율적으로 사용할 수 있다. redis를 캐시로만 사용할 때는 큰 장점으로 다가온다.
단점: 싱글 스레드이기 때문에 병목현상이 발생할 수 있다. 실수로 keys *와 같은 명령어를 입력이라도 하는 날에는 나머지 작업이 계속 밀려 운영에 큰 차질이 생길 것이다.
사용 팁
1. keys * 명령어는 scan 명령어로 대체하여 사용하도록 하자
2. hash 나 set의 경우 한 개의 key에 여러 개의 데이터를 저장할 수 있는데, 이능 성능 저하의 요인이 된다.
따라서 한 개의 키에 최대 100만개 이상의 데이터를 저장하지 않도록 한다.
- 만약 한 키에 100만개 이상의 데이터가 들어있다면 del 명령어를 입력했을 때 해당 데이터를 삭제하는 동안 아무런 동작도 할 수 없게 된다. 이럴 경우 unlink 커맨드를 통해 백그라운드에서 key를 삭제해 주도록 하자.
3. redis를 캐시로 사용할 때는 반드시 EXPIRED TIME을 설정해 주도록 하자.
4. replica를 사용할 경우 MaxMemory는 실제 메모리의 절반으로 설정하자.
- RDB나 AOF 를 만들 때 백그라운드에서 데이터를 파일로 저장하는데 기존 메모리는 그대로 일반적인 요청을 받고 있기 때문에 메모리를 두 배로 사용하는 경우가 발생할 수 있다. 따라서 실제 메모리의 최대치를 넘지 않기 위해 Max Memory는 절반으로 설정해 주는 것이 낫다.
오늘은 redis의 기본적인 특징에 대해 간단하게 알아보았다.
다음 포스트에선 redis를 캐시로 사용하여 프로젝트에 적용시키는 방법을 알아보겠다.
'Tools & Libraries > redis' 카테고리의 다른 글
| redis로 토큰 재발급과 로그아웃 구현하기 - 3 (Spring boot에 적용하기 2) (0) | 2024.07.26 |
|---|---|
| redis로 토큰 재발급과 로그아웃 구현하기 - 2 (Spring boot에 적용하기) (0) | 2024.07.25 |