반응형
AWS SES - Simple Email Service
- 이메일을 보내는데 사용된다.
- SMTP 프로토콜을 사용하며, AWS SDK로 이메일을 보낼 수 있다.
- 여러 서비스와 통합이 가능하다.
- S3
- SNS
- Lambda
- 이메일을 발신, 수신하려면 IAM이 필요한데, IAM과도 통합이 되어 있다.
OpenSearch Service
- ElasticSearch의 후속작이다.
- 다이나모 DB에서 인덱스나 기본키를 이용해서 데이터를 쿼리할 수 있다.
- 하지만 opensearch를 사용하면 이부만 매칭되어도 모든 필드를 검색할 수 있다.
- 예를 들어서 TAVE를 검색하고자 할 때, 기존 다이나모 디비는 정확히 매칭되는 키를 사용해서 TAVE 값을 가져와야 했다면,
openSearch는 TA만 검색해도 TAVE를 가져올 수 있다는 의미이다.
- 검색 뿐만 아니라 분석적 쿼리도 가능하다.
- 데이터 저장소 역할도 하기 때문에, 클러스터가 존재하고 두 가지 모드가 존재한다.
- managed cluster: 말 그대로 사용자가 직접 리소스를 제어하는 방식이다.
- serverless cluster: 서버리스로 사용자가 클러스터에 대해 신경을 쓸 필요가 없다.
- 고유한 쿼리 언어가 존재한다.
- SQL을 네이티브하게 지원하지는 않지만, 플러그인을 통해 SQL과 호환되게 만들 수 있다.
- 다양한 곳에서 온 데이터를 받을 수 있다.
- 키네시스 데이터 파이어호스
- IOT
- CloudWatch Logs
- 기타 커스텀 앱,,
- cognito, iam, KMS, TLS를 통해 보안을 확보할 수 있다.
- 대시보드를 통해 시각화 자료도 만들 수 있다.
일반적인 패턴

- 다이나모 디비에 데이터가 들어있다.
- 다이나모 디비에 CRUD가 실행된다.
- 모든 스트림을 다이나모 디비 스트림에 전송한다.
- 그걸 람다 함수가 캐치한다.
- 람다함수는 데이터를 실시간으로 아마존 openSearch에 삽입한다.
- 검색에 필요한 최소한의 데이터만 저장을 한다.
- ec2는 api 호출을 통해 항목 openSearch에서 항목 ID를 획득한다.
- 항목 ID를 통해 다이나모 디비 테이블로부터 전체 항목을 받게된다.

- 위와 같은 방식으로 CloudWatch에 저장된 로그를 읽어올 수도 있다.
Amazon Athena
- S3 버킷에 저장된 데이터의 분석을 도와주는 서버리스 쿼리 서비스이다.
- 데이터를 분석하려면 표준 SQL언어를 사용해 파일을 쿼리해야 한다.
- Athena는 Postgre엔진으로 구축이 되어 있다.
- 데이터를 옮기지 않고 Athena에서 바로 S3에 쿼리를 날려 분석을 실시할 수 있다.
- 지원하는 파일 포맷은 CSV, JSON, ORC, Avro, Parquet 등으로 다양하며
- 요금 정책도 매우 단순하다.
- 1TB의 데이터를 스캔할 때마다 고정된 비용이 지출된다.
- 보통 Amazon QuickSight라는 도구와 함께 사용해 보고서 및 대시보드를 생성한다.
- 임의 쿼리 실행, 비즈니스 인텔리전스, 분석, 보고, AWS에서 생성된 모든 종류의 로그를 쿼리하고 분석하는 데 사용한다.
- Vpc 흐름 로그, 로드밸런서 로그, CloudTrail 등을 분석할 수 있다.
Amazon Athena - 성능 개선
- 먼저 1TB의 데이터를 스캔할 때마다 비용을 지불해야 하므로, 적절한 데이터 유형을 선택해
데이터 스캔이 적게 일어나도록 해야 한다.- 이럴 때는 열 기반 데이터를 사용하면 비용을 아낄 수 있다.
- 필요한 열만 스캔하면 되기 때문이다.
- 따라서 Athena에 적합한 데이터 포맷은 Apache Parquet과 ORC이다.
- Apache Parquet, ORC로 데이터 포맷을 변경하려면 Glue 서비스를 사용할 수 있다.
- 스캔하는 데이터의 양을 줄이기 위해 데이터를 압축해 반환 용량의 크기를 줄여야한다.
- 데이터를 압축하는 데 사용할 수 있는 방법은
bizip2, gzip, lz4, snappy, zlip, zstd 등이 있다.
- 데이터를 압축하는 데 사용할 수 있는 방법은
- 특정 열에 계속해서 쿼리를 보내야 하는 상황이라면 데이터 세트를 분할할 수 있다.
- 데이터를 분할하려면, 전체 경로 뒤에 슬래시를 붙이고, 각 슬래시에 분할할 열 이름과 값을 넣으면 된다.


- 다음 예시를 보면 년도로 분할하고, 월로 분할하고, 일로 분할해서 폴더를 하나씩 만든 걸 확인할 수 있다.
- 이제 Athena에서 특정 연, 월, 일로 필터링하면 해당하는 데이터만 가져올 수 있다.
- 마지막으로 적용 가능한 방법은 큰 파일을 사용해 오버헤드를 최소화 하는 것이다.
- Ahtena는 작은 파일 여러 개를 저장하는 것보다 128MB 이상의 큰 파일이 있을 때 성능이 더 좋다.
- 사이즈가 큰 파일이 스캔하기도 쉽고, 반환하기도 쉽기 때문이다.
Amazon Athena - Federated Query
- 연합 쿼리 기능이다. S3 뿐만 아니라 모든 곳에서 데이터 쿼리가 가능하다.
- 관계형 또는 비 관계형 DB에 있는 데이터와 AWS 또는 온프레미스에 있는 객체 및 사용자 정의 데이터 소스도 가져올 수 있다.
- 데이터 소스 커넥터를 사용해서 가져올 수 있다.
- 람다 함수를 사용해 람다 함수가 다른 서비스에 연합 쿼리를 실행하도록 만드는 것이다.

- 실행한 쿼리의 결과는 추후 분석을 위해 S3에 저장된다.
Amazon Managed Streaming for Apache Kafka
- 아파치 카프카용 관리형 스트리밍 서비스인 MSK를 살펴보도록 하자.
- 카프카는 Kinesis와 같은 역할을 한다. 둘 다 데이터를 스트리밍 할 수 있다.
- MSK를 사용하면 AWS에서 완전관리형 카프카 클러스터를 구성할 수 있고,
클러스터를 생성, 업데이트, 삭제가 가능하다.- 클러스터에 카프카 브로커 노드와 ZooKeeper 브로커 노드를 생성해 관리하고,
해당 MSK 클러스터를 VPC와 여러 AZ에 배포할 수 있다. - 최대 세 곳에 배포 가능하다.
- 일반적인 카프카 실패로부터 자동으로 복구할 수 있으며, 데이터는 원하는 기간만큼
EBS 볼륨에 저장 가능하다.
- 클러스터에 카프카 브로커 노드와 ZooKeeper 브로커 노드를 생성해 관리하고,
- MSK를 서버리스로 쓸 수 있는 옵션이 있다.
- MSK에서 아파치 카프카를 실행하는 건 동일하지만 모든 리소스 프로비저닝과
컴퓨팅 환경, 스토리지를 알아서 조절한다.
- MSK에서 아파치 카프카를 실행하는 건 동일하지만 모든 리소스 프로비저닝과

- 카프카는 여러 개의 브로커로 구성돼있다.
- 여러 서비스에서 데이터가 생성되면, 브로커에 해당 topic을 작성한다.
- 메세지를 전달받은 브로커는 다른 브로커에 메시지를 복사한다.
- 소비자는 특정 topic을 폴링해서 원하는 곳에 사용한다.
Kinesis Data Streams VS Amazon MSK
- 메시지 크기
- 키네시스 데이터 스트림은 메시지 크기가 1MB로 제한되어 있다.
- MSK는 기본이 1MB이고, 설정을 통해 크기를 더 늘릴 수도 있다.
- 키네시스는 샤드라는 개념을 사용하고, MSK는 파티션과 토픽이라는 개념을 사용한다.
- 데이터 규모 조절
- 키네시스는 샤드를 분할하거나, 샤드를 합쳐서 데이터 송 수신을 원할하게 스케일링한다.
- MSK는 토픽 규모를 조정할 수 있는 방법이 파티션 추가뿐이고, 파티션 삭제는 불가능하다.
- 전송중 암호화
- 키네시스는 TLS를 사용한다.
- MSK는 평문 또는 TLS를 사용한다.
- 저장 데이터 암호화는 둘 다 KMS를 사용한다.
MSK Consumers
- 데이터를 추가하려면 카프카 프로듀서를 만들어야 한다.
- MSK에서 데이터를 가져오는 건 여러 방법으로 할 수 있다.

- 키네시스와 아파치 플링크
- 글루와 아파치 스파크 스트리밍
- 람다 함수
- 서버에 아파치 consumer 직접 실행하기
- 이렇게 네 가지 방식으로 가능하다.
AWS Certificate Manager (ACM)
- 이 서비스를 통해 SSL, TLS 인증서를 쉽게 프로비저닝, 관리 및 배포할 수 있다.
- 이 인증서는 HTTPS 엔드포인트를 제공하고, 웹사이트에서 전송 중 암호화를 할 때 사용된다.
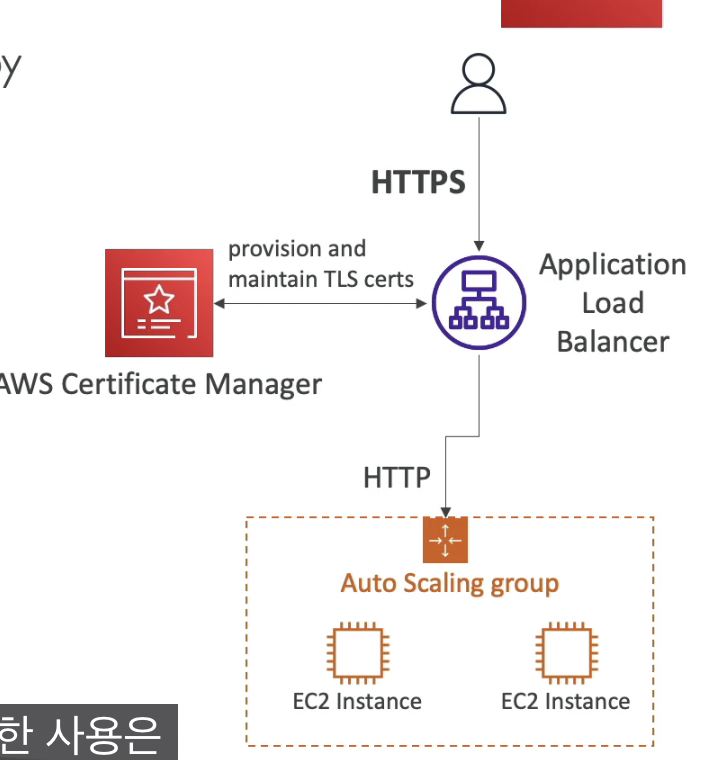
- 로드 밸런서의 HTTPS 엔드포인트를 통해 클라이언트와 통신하고 싶은 상황이다.
- AWS Certificate Manager는 도메인과 연결하여 인증서의 프로비저닝과 유지관리를 지원한다.
- 그러면 이들이 로드밸런서와 연결되고, 로드밸런서가 자동적으로 클라이언트에게 HTTPS 엔드 포인트를 제공하게 되어
공용 웹을 거쳐 전송 중 암호화가 가능하게 된다.- Tcp 핸드 셰이킹 이후 ssl / tls 핸드 셰이킹 과정이 이뤄진다.
이 과정에서 서로의 인증서를 확인하고 암호화 알고리즘을 교환하여 암호화 전송이 가능해진다.
- Tcp 핸드 셰이킹 이후 ssl / tls 핸드 셰이킹 과정이 이뤄진다.
- 공용 및 사설 인증서를 모두 제공하며, 공용 인증서는 무료다.
- 인증서 자동 갱신이라는 아주 편리한 기능도 갖추고 있다.
- 통합이 가능해서 TLS 인증서를 다른 서비스에서도 로딩해준다.
AWS Private Certificate Authority (CA)
- 사설 인증서를 발급하려면 CA를 구성해야 한다.
- 이는 관리형 서비스로, 이를 사용해 루트 인증기관 또는 하위 인증기관을 생성할 수 있다.
- 여기서 엔드 엔티티 x.509 인증서를 발급해 배포할 수 있다.
- 즉 애플리케이션에서 사용할 수 있는 인증서라는 뜻이다.
- 이 인증서는 AWS 조직 내에 있는 애플리케이션에서만 신뢰할 수 있다.
- 사설 인증기관을 신뢰하도록 설정된 경우에 한해서
- 즉, 내부망에서만 사용할 수 있는 인증서라는 뜻이다.
- 주로 내부 인터넷에서 암호화 전송을 위해 사용된다.
- 이 인증서는 공용 인터넷에 배포할 수 없다.
- 추가로 사용중인 AWS 서비스에서 로드밸런서와 같은 ACM을 지원하고 있다면
거기에 사설 인증서를 로드해 사용할 수 있다. - 주로 사용되는 곳은 내부적으로 암호화된 TLS 통신을 사용하는 경우나
코드에 암호화 서명을 적용하는 경우, 사용자 또는 컴퓨터 및 API 엔드 포인트 장치 인증을 위해 인증서를 제공해야 하는 경우이다.
Amazon Macie
- 완전 관리형 데이터 보안 및 데이터 프라이버시 서비스다.
- 머신러닝과 패턴 매칭을 이용해서 민감한 정보를 발견하고 보호한다.
- PII라 불리는 개인식별 번호나 민감 데이터에 대한 경보를 제공한다.

버킷에 저장된 정보를 자동으로 분석해서 민감 정보를 분류하고 해당 데이터를 아마존 이벤트 브릿지를 통해 사용자에게 알린다.
AWS AppConfig
- 애플리케이션의 구성 정보를 보통 함께 배포하거나 환경 변수를 사용해 구성 정보를 모듈화 한다.
- 구성 데이터를 앱 외부에 두고 싶을 때 이 서비스를 사용한다.
- appconfig를 사용하면 앱을 구성 및 검증하고 구성 데이터를 동적으로 배포할 수 있다.
- 구성 데이터를 변경하면 자동으로 애플리케이션에 변경 정보가 반영된다.
- 기능 플래그를 사용할 수 있다.
- 애플리케이션에 새로운 기능을 추가했는데, 지금 당장은 비활성화 하고 싶다고 해보자
- 그럼 앱을 그냥 배포하고 Appconfig에서 해당 기능만 꺼두면 된다고 한다.
- 나중에 기능 플래그 설정을 바꾸면 애플리케이션이 자동으로 해당 기능을 활성화 시킨다.
- 차단할 ip 목록이나 허용할 ip목록도 여기서 실시간으로 반영시킬 수 있다.

- 인스턴스에서 주기적으로 config의 변경사항을 폴링한다.
- 폴링해오면 클라우드 워치가 트리거되고, 에러가 발생하는지 체크한다.
- 만약 에러가 발생했다면, config 구성을 롤백시킬 수 있다.
CloudWatch Evidently
- 앱의 새로운 피처를 테스트할 수 있게 해주는 CloudWatch의 기능이다.
- 사용자의 일부에게만 그 피처를 제공하는 기능이다.
- 위험을 줄이려고 사용한다.
- 5%의 사용자에게만 특정 기능을 배포해서 결과를 파악할 수 있다.
- 실험데이터를 수집해서 분석하고 성능 모니터링을 통해 개선한다.
- Launches(feature flags): 일부 사용자에게 피처를 활성화하거나 비활성화 할 수 있다.
- 일부 사용자가 앱에 코멘트를 달도록 할 수도 있다.
- Experiments(A/B testing): 버튼이 왼쪽에 있으면 어떨지, 오른쪽에 있으면 어떤지, 뭐가 가장 효과적인지 비교하는 것이다.
- 베타테스터를 특정하고 싶을 때는 Overrides 기능을 사용한다. 위의 기능은 랜덤으로 테스터를 정하기 때문이다.
- 사용자 ID 같은 걸 제공해서 그 유저에게만 특정 버전을 보여주도록 한다.

반응형
'AWS' 카테고리의 다른 글
| [AWS] aws 강의 섹션 23 (API GateWay) (0) | 2025.02.04 |
|---|---|
| [AWS] aws 강의 섹션 15 (CloudFront [CDN Service]) (0) | 2025.01.22 |
| [AWS] aws 강의 섹션 30 (KMS, SSM Parameter Store, CloudHSM, Nitro Enclaves) (1) | 2024.12.26 |
| [AWS] aws 강의 섹션 29 (고급 IAM 정책) (2) | 2024.12.18 |
| [AWS] aws 강의 섹션 28 (Step Function, AppSync, Amplify) (4) | 2024.12.05 |