Amazon S3
- S3는 무한으로 확장이 가능하다 하며, 상당히 많은 웹에서 S3에 의존하고 있다.
- S3를 백본으로 많이 사용한다.
S3 사용 사례
- 백업이나 스토리지 용도로 많이 사용된다.
- 재해 복구로도 사용된다.
- 기록 보관용으로도 사용된다.
- 하이브리드 클라우드 스토리지 역할도 한다.
- 애플리케이션 호스팅
- 미디어 호스팅
- 대량의 데이터를 저장하고 데이터 분석
- 소프트웨어 업데이트
Buckets
- S3는 파일을 버킷에 저장한다.
- 버킷은 최상위 디렉토리 개념이다.
- 버킷에 담기는 파일들은 객체라 불린다.
- 버킷은 계정에 생성되고 전역적으로 고유한 이름을 가지게 된다.
- 가지고 있는 계정에 속한 모든 리전에서 고유한 것이다.
- 또한 AWS에 속한 모든 계정에서도 고유하다.
- 버킷은 리전 단위로 정의된다.
- 모든 단위에서 고유하다 할 지라도 버킷 생성은 특정 AWS 리전에서 해줘야 한다.
- S3가 글로벌 서비스 같아 보이지만 리전안에서 생성해야 한다.
- 버킷 이름엔 대문자나 _가 불가능 하고
- 길이는 최소 3자에서 최대 63자까지 가능하고
- IP 주소를 이름으로 사용하면 안 된다.
- 소문자나 숫자로 시작해야 하며 접두사 접미사 규칙도 있다.
- 글자, 숫자, 하이픈으로만 이름을 만들면 된다.
S3 객체
- 객체란 파일을 의미한다.
- 각각 키를 가지고 있고, 해당 키는 경로와 같은 의미여서
키를 통해 객체를 찾을 수 있다. - 만약 S3://mybucket/myfile.txt가 있다고 하면
여기서 mybucket은 버킷 이름 myfile.txt는 키가 된다.

이 예시에선 파란색 부분이 키가 된다.
- 키는 접두사와 객체 이름으로 구성된다.

- 이 예시를 보면 노란 부분이 접두사 파란 부분이 객체 이름이다.
- S3엔 디렉토리 개념이 없다.
- S3의 모든 것은 다 하나의 키이고, 키는 매우 긴 이름일 뿐이다.
- /가 들어간 이름이고, 키는 접두사와 객체 이름으로 구성된다.
- 객체란 파일의 내용이다.
- 원하는 아무 파일이나 S3에 업로드 할 수 있는데
- 객체의 최대 크기는 5TB이다.
- 만약 5GB를 넘는 파일을 저장하려면 업로드 할 때 멀티 파트 업로드라는
기능으로 파일을 여러 부분으로 나눠 올려야 한다.- 5TB를 올린다면 5GB 1000개로 올려야 한다.
- 객체는 메타 데이터를 가질 수 있는데
- 키-밸류 형태이고
- 파일의 특정 속성에 대한 값으로 시스템이나 유저가 설정할 수 있다.
- 객체는 태그를 가질 수 있다.
- 유니코드 키-밸류 형태이고
- 최대 10개 까지 붙일 수 있다.
- 보안이나 수명 주기 관점에서 유용하다
- 버전 아이디를 가질 수도 있다.
S3에 올린 객체는 퍼블릭 url을 통해 접근할 수 없다.
자격증명된 presigned url로만 접근할 수 있다.
퍼블릭 url로 접근하게 하려면 객체를 공개로 설정하면 된다.
S3 보안
- 사용자 기반
- 사용자 단위로 IAM 정책을 적용할 수 있다.
- IAM 정첵은 어떤 사용자가 어떤 API를 호출할 수 있는지 정의한 것이다.
- 자원 기반
- bucket policies: S3 콘솔에서 버킷에 권한을 설정하는 것이다.
특정 사용자나 특정 계정에 속한 사용자에게 권한을 주는 것이다.
이 방법으로 S3 버킷을 퍼블릭으로 설정할 수 있다. - Object Access Control List (ACL): 보다 세밀한 보안체계다. 비활성화도 가능하다.
- Bucket Access Control List (ACL): 버킷 단위로 액세스를 제한하는 것이다.
잘 안 쓰는 방법이며 역시 비활성화가 가능하다.
- bucket policies: S3 콘솔에서 버킷에 권한을 설정하는 것이다.
- 가장 많이 사용하는 보안은 버킷 정책이다.
IAM 사용자는 어떤 상황에 S3 버킷에 접근이 가능할까
- IAM 권한에 접근이 허용돼 있거나 자원 정책에 해당 자원 접근이 허용돼 있거나
명시적 거부 액션이 없다면 IAM 사용자는 허용된 API를 호출해 S3 객체에 접근할 수 있다.
또 다른 보안 적용 방법은 암호화 키를 이용해 객체를 암호화 하는 것이다.
S3 버킷 정책
JSon으로 작성돼 있다.

하나 하나 살펴보자
- Resource: 정책이 적용되는 버킷 그리고 객체를 나타낸다.
- 위의 정책은 examplebucket 안의 모든 객체에 접근을 허용하고 있다.
- Effect: 허용 또는 거부를 의미한다.
- Actions: 허용하거나 거부할 API를 명시한다.
- Principal: 정책을 적용할 사용자나 계정을 명시한다.
위의 정책은 examplebycket 내부의 모든 객체를 get 할 수 있는 권한을 의미한다.
적용대상은 *이므로 모두에게 공개한다는 의미다 즉 버킷을 퍼블릭으로 설정한 것과 같다.
- 다른 옵션도 사용할 수 있다.
- 버켓을 퍼블릭으로 설정하여 모두가 접근 가능하게 함
- 객체를 업로드 할 때 암호화를 강제할 수 있다.
- 다른 계정에 접근 권한을 줄 수도 있다.
EC2에서 S3에 접근하고 싶을 때
IAM Role을 활용하면 된다.
- EC2 인스턴스 Role을 생성하고 해당 Role에 S3 접근 권한을 부여해주면
- EC2 인스턴스는 S3 버킷에 접근할 수 있다.
계정 간 액세스를 허용하고 싶을 때
이런 경우는 버킷 policies를 사용하면 된다.
다른 유저가 버킷에 접근하게 하려면
- S3 버킷 정책에 계정 간 액세스 권한을 명시해줘야 한다.
bucket settings for block public access
aws에서 데이터 유출을 막기 위해 한 단계 추가로 덧씌운 보호막이다.
- S3 버킷 정책에서 퍼블릭 액세스를 명시해두어도
- 해당 설정이 활성화돼 있으면 버킷은 퍼블릭으로 동작하지 않는다.
- 어떤 버킷도 공개하길 원치 않는다면 해당 설정을 그대로 두면 된다.
- 계정에서 설정을 할 수도 있는 옵션이다.
S3로 정적 웹사이트 배포하기
- s3는 정적 웹사이트를 배포할 수 있다.
- 주소는 어느 리전에서 생성하느냐에 따라 다르다

- 버킷에 담긴 html 파일이라던가 이미지 파일로 웹사이트를 호스팅할 수 있다.
- 물론 퍼블릭 읽기 권한이 허용돼 있지 않으면 웹사이트에 접근이 불가능 하다.
S3 버전 관리
- 파일에 버전을 메길 수 있다.
- 버전 기능은 버킷 단위에서 설정할 수 있다.
- 파일을 업로드 할 때 선택한 키로 파일의 버전이 정해진다.
- 같은 키를 가지고 다른 파일을 업로드 하면, 버전 2, 버전3 등이 만들어진다.
- 당연히 덮어씌워지는게 아니다.
- 버전관리를 사용하면 여러 이점이 있다.
- 의도치 않은 삭제에 대응 가능 (delete marker 활용)
- 쉬운 복구가 가능함
버전 관리 기능을 중간에 활성화 시키면 버전 관리 기능을 활성화 하기 전에 있던 파일들은
버전 값이 null로 설정됨
버전 관리 기능을 멈춰도 이전 버전이 삭제되진 않음
S3 복제 (CRR, SRR)
CRR은 서로 다른 리전 복제를 의미하고
SRR은 동일 리전 복제를 의미한다.
- 복제는 비동기로 이뤄진다.
- 양쪽 모든 버킷에 버전 관리를 활성화 해야 한다.
- 다른 계정에 있는 버킷도 복제가 가능하다.
- 복제는 백그라운드 작업으로 진행된다.
- 복제가 제대로 되려면 S3 서비스에 알맞는 IAM 권한을 부여해야 한다.
- 해당 버킷에서 읽기 쓰기 기능이 활성화 돼있어야 한다.
CRR 사용 예시
- 컴플라이언스, 저지연 액세스, 다른 계정 간 복제
SRR 사용 예시
- 로그 집계, 운영 계정과 테스트 계정 사이 라이브 복제
S3 복제 주의점
- 복제 기능을 활성화 한 다음에 생성한 객체만 복제가 된다.
- 활성화 이전에 넣어뒀던 객체들은 복제 안 됨!
- 기존에 있던 객체를 복제하려면 S3 배치 복제 기능을 이용해야 한다.
- 삭제 작업도 복제할 수 있다.
- delete 마커 복제 가능 (기본적으로 delete 마커는 복제되지 않는다.)
- 삭제된 것이 특정 버전이라면 복제되지 않는다. (영구 삭제인 경우는 복제되지 않는다는 뜻)
- 복제 체이닝은 지원되지 않는다.
- A가 B를 복제하고 C가 B를 복제한다고 했을 때
- A에서 업데이트된 내용은 C에 올라가지 않는다.
S3 Storage Class
- S3 Standard - General Purpose
- S3 Standard - Infrequent Access
- S3 One Zone - Infrequent Access
- S3 Glacier Instant Retrieval
- S3 Glacier Flexible Retrieval
- S3 Glacier Deep Archive
- S3 Intelligent Tiering
또한 객체를 생성할 때 객체 클래스도 선택할 수 있다.
스토리지 클래스는 수동으로 바꿀 수 있다.
S3 수명 주기 설정으로 객체가 자동으로 이 클래스들 중 하나가 되게 할 수 있다.
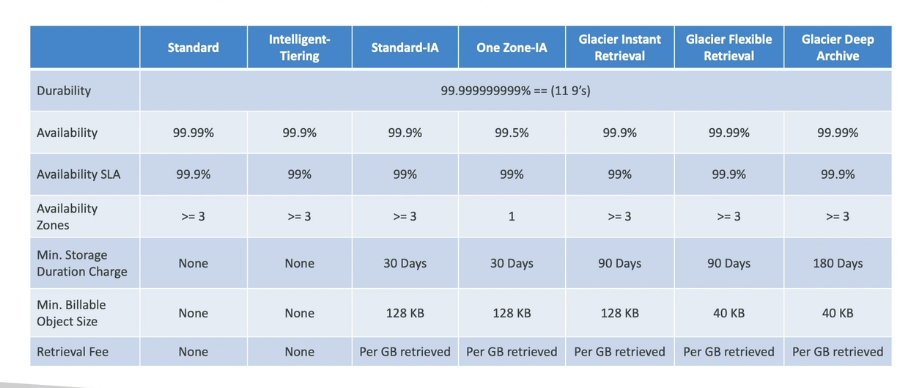
내구성과 가용성 (Durability and Availability)
내구성
- S3가 객체를 잃을 가능성을 의미한다.
- S3의 내구성은 매우 높다
- 9가 총 11개로 99.999999999%의 확률로 객체를 잘 보관한다.
- 만약 천 만개의 객체를 S3에 저장하면 잃어버리는 객체는
- 만 년 마다 한 개다.
- 스토리지 클래스 종류와 관계 없이 내구성은 동일하다.
가용성
- 서비스를 얼마나 사용 가능한지를 의미한다.
- 스토리지 클래스 별로 가용성이 다르다.
- S3 Standard - 99.99%의 가용성 = 연간 53분 정도 서비스를 이용할 때 에러가 생긴다는 의미
S3 Standard - General Purpose
- 가용성이 99.99%다.
- 자주 액세스 하는 데이터를 저장하는 데 쓴다.
- 보통 기본으로 사용하는 스토리지다.
- 지연 시간이 짧고 쓰루풋은 높다.
- 두 개의 데이터 센터에 장애가 동시에 발생해도 데이터를 안전하게 유지할 수 있다.
사용 예시: 빅데이터 분석, 모바일 앱, 게임, 콘텐트 배포 ,,
S3 Infrequent Access (S3 Standard - IA)
- 덜 자주 사용하는 데이터용이다. - 그러나 데이터 접근 속도는 빠르다
- standard 보다는 비용이 적지만 데이터를 조회할 때 비용이 발생한다.
- 가용성은 99.9% 이다. 스탠다드 보다는 적다.
사용 예시: 재해 복구, 백업
S3 One Zone Infrequent Access (S3 One Zone - IA)
- 내구성은 위에 말했던 것과 동일하게 9가 11개다 (한 개의 가용영역 안 에서)
- 해당 한 개의 가용영역이 어떤 이유에서든지 파괴된다면 데이터 손실이 발생한다.
- 가용성은 99.5%이다. 상당히 낮아졌다.
사용 예시: 온프레미스 데이터의 재생성할 수 있는 데이터의 백업 사본 용도 즉, 잃어버려도 되는 데이터
S3 Glacier Storage Classes
차갑다.
- 저렴한 객체 스토리지로 아카이브나 백업을 위한 클래스다.
- 스토리지당 비용이 발생하고, 검색 할 때마다 건 당 비용이 발생한다.
- Glacier 클래스의 종류가 세 개 존재한다.
- S3 Glacier Instant Retrieval
- 밀리초 단위로 검색을 할 수 있다.
- 분기당 한 번 액세스 하는 데이터에 적합하다.
- 최소 스토리지 기간은 90일이다.
- 백업용인데 밀리초 단위로 액세스 해야하는 데이터가 대상이다.
- S3 Glacier Flexible Retrieval (formerly Amazon S3 Glacier)
- 3개의 검색 옵션을 가지고 있다.
- Expedited - 데이터 검색에 1~5분이 소요된다.
- Standard - 데이터 검색에 3~5시간이 소요된다.
- Bulk - 데이터 검색이 무료지만 5~12시간이 소요된다.
- 최소 스토리지 기간은 90일이다.
- 3개의 검색 옵션을 가지고 있다.
- S3 Glacier Deep Archive - for long Term storage
- 두 개의 검색 옵션이 있다.
- Standard - 12시간이 걸린다.
- Bulk - 48시간이 걸린다.
- 데이터를 검색하려면 무척 오래 기다려야 하지만 비용이 제일 저렴하다.
- 최소 스토리지 기간은 180일이다.
- 두 개의 검색 옵션이 있다.
클래스 이름에 Instant가 있다면 데이터를 바로 검색한다는 의미고,
클리스 이름에 Flexible이 있다면 데이터 검색을 기다릴 의향이 있다는 의미다.
S3 Intelligent - Tiering
- 사용 패턴에 따라 자동으로 적절한 티어에 객체를 이동시킨다.
- 월별 객체 모니터링 비용과 자동 객체 이동 비용이 발생한다.
- 검색 비용은 별도로 발생하지 않는다.
- 티어 종류는 다음과 같다.
- Frequent Access tier - 빈번한 액세스에 적합하다. (default 값이다.)
- Infrequent Access tier - 빈번하지 않은 액세스에 적합하다. (30일간 액세스 하지 않은 객체 대상)
- Archive Instant Access tier - 90일 동안 액세스 되지 않은 객체가 자동으로 이동하는 티어다.
- Archive Access tier (선택사항) - 액세스 하지 않은 기간을 90~700일 이상으로 설정할 수 있다.
- Deep Archive Access tier (선택사항) - 180~700일 이상으로 설정할 수 있다.
- 위에 써놓은 조건에 걸리면 자동으로 티어가 변경된다.